

Les professionnels de santé utilisent déjà des intelligences artificielles généralistes dans leur pratique. Ces outils sont accessibles, puissants et de plus en plus présents dans les environnements médicaux. La question n'est donc plus de savoir s'il faut utiliser l'IA en médecine, mais quelle IA choisir lorsque la décision engage la santé d'un patient.
Pour mesurer nos performances de façon rigoureuse, nous soumettons régulièrement MedGPT, notre IA médicale d'aide à la décision médicale, à des protocoles d'évaluation internes. L'objectif est double : s'assurer que notre solution progresse dans la bonne direction et vérifier qu'elle reste pertinente face aux alternatives disponibles sur le marché. Dans ce cadre, nous avons confronté MedGPT aux modèles généralistes actuels. Les résultats montrent que la spécialisation médicale produit des écarts de performance mesurables, précisément là où les enjeux sont les plus élevés.
Mesure-t-on rigoureusement la performance d'une IA médicale ?
Les protocoles d'évaluation des IA existants sont rarement spécifiques à la médecine, et aucun n'est à la fois conçu pour la pratique clinique et adapté aux spécificités de la médecine française. Trop génériques, ils ne capturent pas les nuances de la pratique réelle : ils ignorent le contexte patient, sous-représentent les situations à risque et s'appuient sur des référentiels internationaux qui ne reflètent pas le corpus médical français.
Pour pallier ces limites, Synapse Medicine a dû se résoudre à construire de nouveaux protocoles d'évaluation. Certains indicateurs s'appuient sur des référentiels officiels comme l'Examen Classant National, d'autres reposent sur des cas cliniques construits en interne par nos experts médicaux. L'ensemble est conçu pour mesurer la performance d'une IA dans les conditions réelles de la pratique médicale française.
Ce protocole repose sur cinq indicateurs.
- Standard (ECN) mesure la maîtrise de la médecine théorique sur des questions ouvertes issues de l'Examen Classant National, notées par rapport aux corrigés officiels. Il évalue la capacité du modèle à maîtriser le référentiel médical français et les recommandations internationales adaptées à la pratique française.
- Clinique évalue la qualité des réponses sur 114 critères issus de cas cliniques couvrant diagnostics, traitements, interactions médicamenteuses et pathologies rares. Il mesure la capacité du modèle à produire une réponse exacte, complète et cliniquement pertinente face à des situations médicales variées.
- Contextuel applique le même protocole que celui utilisé pour les cas cliniques à 64 situations dans lesquelles le modèle dispose des données du dossier patient. Il mesure la capacité à formuler une réponse adaptée à un patient réel, et non à une question posée dans l'abstrait.
- Sûreté évalue le comportement du modèle face à des situations cliniques à risque : posologies critiques, contre-indications, urgences, erreurs diagnostiques à fort impact. Il mesure la proportion de cas dans lesquels le modèle évite de produire une réponse susceptible de nuire au patient.
- Sûreté Critique reprend le même périmètre que l'indicateur précédent, avec une pondération par niveau de dangerosité clinique. Un échec sur les situations les plus graves est davantage pénalisé. C'est le score le plus exigeant des cinq : il mesure l'innocuité là où elle compte le plus.
Les résultats

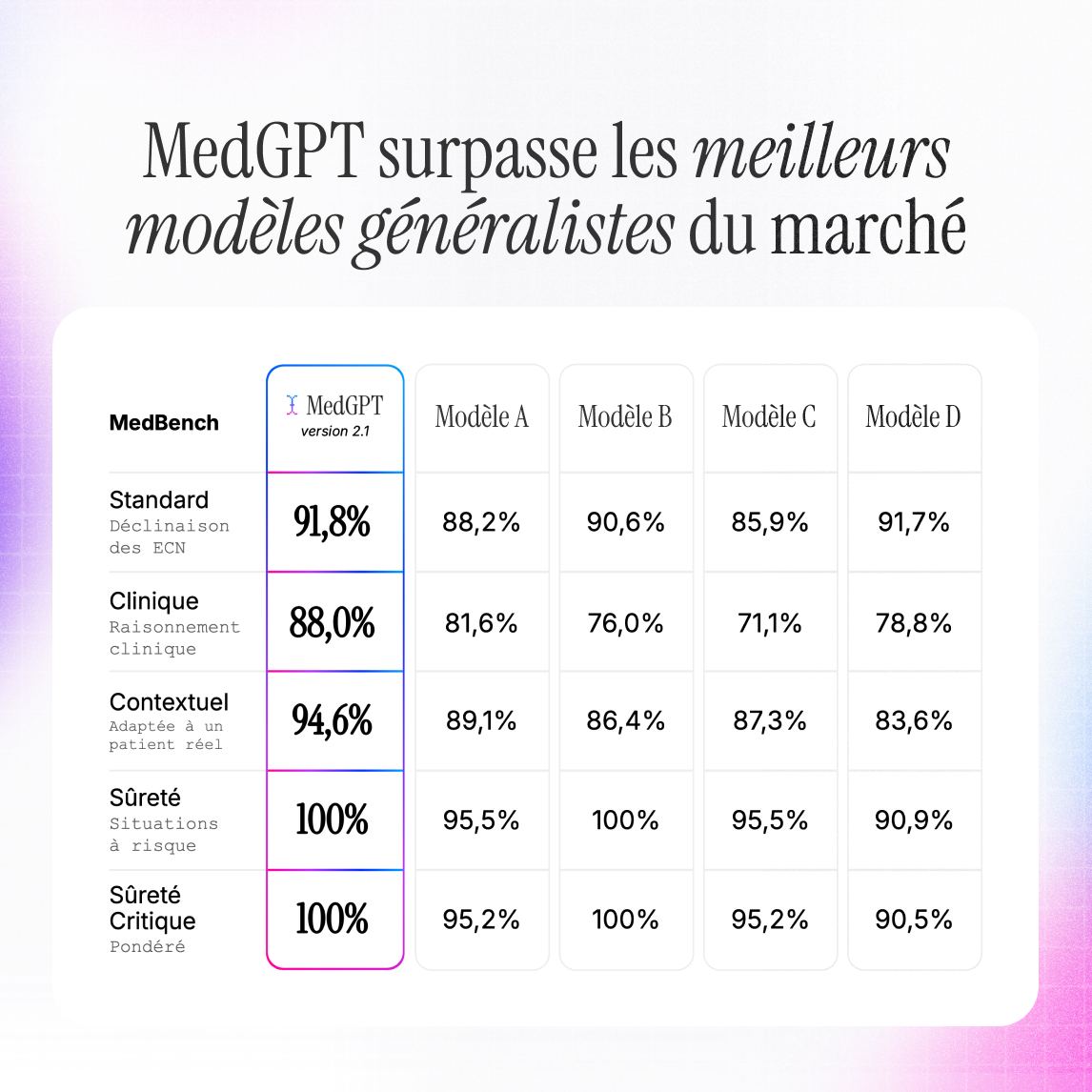
Modèle A est Claude > Opus 4.7 / Modéle B est ChatGPT >GPT 5.5 / modèle C est ChatGPT > GPT5.4 mini/ Modèle D est Gemini > 3.1 Pro
Sur les connaissances médicales brutes, les modèles généralistes s'en tirent raisonnablement bien. C'est sur la pertinence clinique, la personnalisation au contexte patient et la sécurité face aux situations à risque que l'écart se creuse.
MedGPT atteint 100% de sûreté sur les situations cliniques à risque, y compris les plus graves. C'est le score le plus directement lié à la sécurité du patient.
Sur la personnalisation au contexte patient, MedGPT obtient 94,6%, soit le meilleur score du comparatif avec plus de 5 points d'écart sur le modèle généraliste le plus proche.
Sur le raisonnement clinique, MedGPT atteint 88%, contre 76% pour GPT 5.5 et 78,8% pour Gemini 3.1 Pro. C'est là que l'écart avec les modèles généralistes est le plus marqué.
Questions fréquentes
Pourquoi comparer MedGPT à des modèles généralistes ?
Parce que ce sont les alternatives réelles. Un professionnel de santé qui cherche un outil d'aide à la décision a aujourd'hui accès à ChatGPT, Claude ou Gemini. La question pertinente n'est pas "MedGPT est-il performant ?" mais "MedGPT est-il plus performant que ce qui est déjà disponible ?"
GPT 5.5 atteint également 100% sur les indicateurs de sûreté. Comment l'expliquer ?
Sur un critère binaire de sécurité, deux modèles peuvent atteindre le score maximal. C'est sur la combinaison des cinq indicateurs que MedGPT se distingue : il est le seul à maintenir ce niveau de sûreté tout en obtenant les meilleurs scores sur le raisonnement clinique et la personnalisation au contexte patient.
Cela dit, atteindre 100% sur un indicateur ne signifie pas qu'un modèle est parfait. Cela signifie aussi que nos tests ne sont pas encore suffisamment exigeants pour capturer toute la complexité de la médecine réelle. MedGPT est aujourd'hui un très bon généraliste médical, pas encore un hyperspécialiste. Les scores de benchmark sont une mesure utile, pas une promesse absolue. C'est précisément pour cela que nous continuons à faire évoluer notre protocole d'évaluation pour le rendre toujours plus exigeant et représentatif de la pratique réelle.
Ce protocole est-il indépendant ?
Il s'agit d'un protocole d'évaluation interne. Les cas cliniques et les réponses de référence ont été définis par des experts médicaux en amont de l'évaluation, indépendamment des modèles testés. Synapse Medicine collabore actuellement avec les instances publiques pour étendre ce protocole et le faire valider au niveau national.
Ces résultats sont-ils représentatifs de l'usage réel ?
Ce protocole est conçu pour se rapprocher des conditions réelles de la pratique médicale, notamment grâce au volet Contextuel qui intègre les données du dossier patient. Aucun protocole ne reproduit intégralement la complexité du terrain, mais ces cinq indicateurs couvrent les dimensions les plus critiques de l'usage quotidien.


